 |
LibInsane
1.0.3
Cross-platform Cross-API Cross-driver Cross-image-scanner Image Scan Library
|
|
LibInsane
1.0.3
Cross-platform Cross-API Cross-driver Cross-image-scanner Image Scan Library
|
Libinsane provides a single API but has many implementations for it. Most of the time, you will only want the implementation "safebet". It is a composition of many other implementations that will provide a consistent behaviour across all platform and devices.
You're advised to get an implementation when your application starts and clean it up just before your application ends.
The API allows you to obtain a list of devices connected to the computer (with implementation.list_devices()). For each device, it will provide you with a vendor name, a model name, a device type name, and more importantly a device identifier. The device identifier can then be used to access the device (with implementation.get_device()).
LibInsane tries to return only devices that are actually configured and online. If the scanner is shut down or disconnected, it is not returned. However this behaviour is (not yet) guaranteed.
Beware that device IDs may change over time. For instance, with Sane drivers, some IDs include the bus and device numbers: sane:plustek:libusb:002:079, after disconnecting/reconnecting the scanner, may become sane:plustek:libusb:002:080. There is not much Libinsane can do about that. If the scanner ID you're looking for is not available anymore, you may want your application to look for the closest scanner ID it can find.
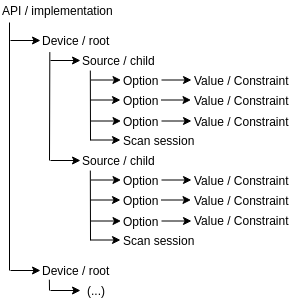
Libinsane provides an item tree (inspired by WIA2):
All items provide a set of options.
implementation.list_devices() will return you a list of device name and ID. Depending of the environment, this function can take up to 30 seconds.
implementation.get_device(device_id) will return a root item (aka a device). When you're done scanning, only this root item will have to be closed. When you close the root item, all the children are closed too and must not be used anymore.
You're advised to get a device only just before wanting to configure and use it or list its options and close it as soon as you're done with it. It's not recommended nor tested to keep a device opened for a long time.
Note that implementation.get_device() may take a few seconds.
root.get_children() will return all the available sources of the device.
Usually you cannot scan using the root item. You should always set the options on the child item (source) you want to use and use that child.
To simplify the use of root and children, all the options available on the root item are also made available on all the children.
Once you have found the child item (source) that you want to use, you have to configure it. Some options are read-only, some options can be modified. Some can have integers as values, some can have strings, etc. Some options have a constraint defining what values are allowed. This constraint can be a range or a list.
Only a small subset of options are guaranteed to be found on any child item (inspired by Sane):
LibInsane offers guarantees only on the options below. All the other options are device-dependant and driver-dependant.
While option 'mode' is not guaranteed to be present on all scanners, it has been seen on all scanners up to now.
If present, Libinsane will normalize 3 of the possibles values: Color (24bits RGB), Gray (grayscale), LineArt (black & white). Other values may be available depending on the scanner and its driver.
If you set mode to Lineart, there may also be an option depth that you must set to 1. This is (not yet) done automatically by Libinsane.
While option resolution is not guaranteed to be present on all scanners, it has been seen on all scanners up to now.
Value is guaranteed by Libinsane to be an integer. Unit is always DPI. Constraint is guaranteed by Libinsane to be expressed as a list of integer values.
Scan area is defined as the value of 4 options:
tl-x: Top left corner of the area that will be scanner. X coordinates.tl-y: Top left corner of the area that will be scanner. Y coordinates.br-x: Bottom right corner of the area that will be scanner. X coordinates.br-y: Bottom right corner of the area that will be scanner. Y coordinates.If you choose to set the scan area, be careful to always keep the tl coordinates at lower values than the br ones. If you don't, you may get an error when setting them.
Once all the options are set, we can finally scan something.
While scanning, your application must not try to list devices nor access any other device nor change the options. If it does, the behaviour of Libinsane and the underlying is undefined.
Using item.scan_start() on a child node, you can obtain a scan session. From a scan session, you can obtain one or more pages / scanner images.
get_scan_parameters() provides information regarding the page being scanned.scan_read() returns the images as raw 24 pixels (even if scanning in black&white or grayscale).end_of_page() indicates that you reached the end of the current page.end_of_feed() indicates that all pages have been scanned.cancel() allows to interrupt the scan session. It can be safely called once the scan session has been finished (end_of_feed() == True). Calling it before may or may not work (it may even causes crahses). If you want to cancel a scan while it's running, you're advised to simply let it end. The session cannot be used once this function has been called.Those functions are intended to be called in the following order:
Duplex scans are simply provided as 2 pages.
scan_read()On GNU/Linux (Sane), scan_read() is pretty much a direct call to sane_read(), which itself is almost a direct call the backend read() function. So during a scan, when you are not calling scan_read(), backend may be unable to do anything. If the backend doesn't communicate with the scanner for too long, communication may time out.
On Windows (WIA/TWAIN), data from the scanner are immediately handled by a dedicated thread and stored in a queue. When you call scan_read(), you are actually getting data from this queue. If you don't call scan_read() often enough, raw data may accumulate in this in-memory queue. This may not be what you want.
Therefore the buffer size depends on what you can process quickly. You don't want to spend too much time processing the data scan_read() returns before calling it again.
On the other end, using a buffer too small means calling scan_read() much more often, which will decrease performances.
The recommended range for the buffer size is 4kB-128kB. By default 64kB is suggested. If you have to do some heavy processing on the chunks coming from the scanner (for instance to display them), you may want to consider doing it in a separated thread.
 1.8.13
1.8.13